Introduction
When Bob Pritchett asked me at the BibleTech 2019 conference what I was working on at the time, I answered that I’d returned to the idea that originally launched this site: Bible geography. When I told him that, I’d intended to present the results of this effort at a presumptive BibleTech 2021 conference. Since the global pandemic has put in-person conferences and travel on hold, however, here are 4,800 words about it instead of a presentation.
If you prefer to jump straight into the data, see the interface or browse the data.
What does rethinking the Bible Atlas mean?
This project is a Bible atlas (technically, a gazetteer) that (1) comprehensively identifies the possible modern locations of every place mentioned in the Bible as precisely as possible, (2) expresses a data-backed confidence level in each identification, and (3) links to open data to fit into a broader data ecosystem. The goal is to provide a baseline for future Bible geography projects to use.
In my original design document for this project, I have the following guiding principles; I’ll discuss their implementation below:
- Comprehensively reflect current scholarship.
- Use linked data.
- Be accurate and precise.
- Quantify uncertainty.
- Handle non-point data.
- Include media.
- Open the data.
Background
I started this site in 2007 with the idea of creating a place that embraced Google Earth as a way of exploring places mentioned in the Bible. I relied on freely available and older public-domain sources to disambiguate and identify modern locations of biblical places, and then I picked the location that looked likeliest to me. The 1899 Morrish Bible Dictionary proved especially helpful because it included latitude and longitude coordinates for many of its entries. Of course, it also reflects a late-nineteenth-century view of biblical and archaeological scholarship.
Over time, I became frustrated with the limited nature of the dataset; I wanted to incorporate modern scholarship, which meant one thing: I needed a budget.
Used Bible atlases are surprisingly cheap; you can find most of them on Amazon for around $10 each. Bible dictionaries and encyclopedias are surprisingly expensive: even digitally, they run $100 or more. Commentaries also add up because there are so many of them. Fortunately, I know people with commentary libraries that I could use, helping keep the cost down:

In the end, my content budget for this project ran about $1,000, and I consulted what I believe to be every significant Bible atlas, dictionary, and encyclopedia published since 1980 (and several before then).

Goal 1: Comprehensively reflect current scholarship
With this variety of sources—over seventy in all—it becomes possible to paint a full(ish) picture of where modern scholars believe biblical places may have been.
My basic method was simple:
- Start with a place mentioned in the Bible.
- Consult a dictionary/encyclopedia article, atlas/gazetteer entry, commentary note, or other reference work related to that place.
- Record every suggestion of possible locations for the place, including the confidence of the suggestion.
- Research coordinates for any modern locations mentioned.
- Repeat steps 2-4 across 70 or so sources.
- Repeat steps 1-5 across all 1,300 places mentioned in the Bible.
In this way, you end up with a set of “votes” from authors that, in principle, reflects the current consensus on where a place was. This approach also removes me from the position of deciding which identifications are more valid than others.
A typical Bible atlas makes around 500 identifications; a large dictionary or encyclopedia might suggest around 1,000. This project records over 3,200 identifications, tallying 23,000 votes across 1,340 ancient places tied to nearly 1,600 possible modern locations.
I use the word “identification” because a source might say that a particular place is another name for a different ancient place, or maybe not even a place at all, so not every vote is for a modern location. The ratio of modern-to-ancient suggestions generally runs around 2:1—in other words, there are usually around twice as many modern suggestions (identifying a specific modern location) as ancient suggestions (identifying a biblical place with another ancient place).
For the purposes of this project, authors have nineteen ways to propose an identification. I particularly want to highlight the different rhetorical strategies of “confidence” vs. “authority.” About 82% of the time, authors will express their own opinion that a certain identification is likely or unlikely. The rest of the time, they’ll appeal to the prevailing consensus, use the passive voice to avoid expressing their own view, or note that someone else has made an identification.
Here’s the schema I used to model this rhetoric.
| Category | Keyword | Common words used |
|---|---|---|
| Confidence | Yes | is, undoubtedly, no doubt, confirmed, is to be identified with, convincingly identified, surely, corresponds to, has been fixed to, no good reason to question, almost universal agreement, is represented by, should be connected with |
| Likely | probably, likely, gazetteer entry without qualification, plausibly identified, evidently, fairly certain, quite possibly, popular, attractive, strongly suggest, suits well, serious candidate, seems to fit, presumably, may well be, strong evidence | |
| Most likely | most likely, most probable, best fit, most suitable, strongest candidate, best current suggestion, least objectionable, best identified, best explained | |
| Map | (coordinates unambiguously match on a map) | |
| Possible | possibly, may, (gazetteer entry with qualification, e.g., “?”), tentatively, preliminarily, provisionally, some scholars, apparently, sought at | |
| Unlikely | unlikely, much less likely, doubtful, tenuous, dubious, problematic | |
| No | not, reject, little to commend it, rule out, abandon, unacceptable, out of the question, impossible, unthinkable | |
| Identified | Is identified | is identified, is believed, is associated with, now identified, is identifiable |
| Has been identified | has been identified, has been inferred, has been linked with | |
| Identified (as an adjective) | identified, suggest, associated with | |
| Authority | Old | formerly, previously |
| Parallel | parallel passage | |
| Preserved | name has been preserved, name is preserved, name survives | |
| Scholar | (another scholar is cited by name) | |
| Traditional | traditionally, historically, (if the tradition predates the nineteenth century) | |
| Usually | generally, usually, most scholars, many scholars, most often, most, customarily, commonly, consensus, gained favor, is thought to be, prevailing identification | |
| Variant | certain translations read | |
| Unknown | Unknown | Unknown |
| Uncertain | Uncertain |
Goal 2: Use Linked Data
A modern Bible atlas doesn’t exist in a data desert; it participates in a network of scholarship both focused on the Bible and also on general history. Linked Data is a way to map data between different datasets—a way to participate computationally in this network of scholarship. This project contains 6,536 Linked Data connections for the ancient places mentioned in the Bible (though, to be fair 1,228 of them are to the 2007 version of this dataset).
About half of the places mentioned in the Bible have a Wikidata entry; I also bring in other ontologies —notably the Bible-oriented Logos Factbook and TIPNR—and Pleiades, the broadly historically focused “community-built gazetteer and graph of ancient places.”
But linking ancient places reflects only half the story: modern locations also have identifiers, and usually coordinates associated with an identifier. Here again I draw on Wikidata but also on modern gazetteers like GeoNames and OpenStreetMap.
In all, 6,473 Linked Data connections support the coordinates for modern locations.
The following are my most-cited sources: Wikidata, Digital Archaeological Atlas of the Holy Land, GeoNames, OpenStreetMap, Amud Anan, Palestine Open Maps, MEGAJordan, Israel Antiquities Authority, and Cultnat.
Goal 3: Be accurate and precise
Most reference works, when they provide coordinates at all, use a 1 km (0.6 mile) resolution—in other words, they get you within 1 km of the actual coordinates of what you’re looking for. Often they just say that a modern location is “near” another one or provide a rough distance and (if you’re lucky) a direction from a larger city. Sometimes, if they’re drawing from nineteenth-century travelogues, a source might say that a location is a certain number of hours (by foot or horse) along a road between two other cities, or they just provide a name with no indication of where it is. The point is that they’re usually (but not always!) accurate—they provide a general sense of where a location is. Unfortunately, they’re not usually precise—telling you exactly where it is.
Fortunately, with modern, public data and gazetteers powered in part by local knowledge, we can do better. Digital sources often provide precise coordinates for ruins visible on the ground. In this dataset, 17% of locations have coordinates with 10 m, 57% within 100 m, 87% within 250 m (matching a modern settlement), and 97% within 1 km. All locations are as precise as I can find support for; some places in Jerusalem (e.g., the Millo) potentially have specific archaeological remains inside the city with exact coordinates.
Additionally, I’ve provided over 1,200 comments on how I came to decide on the coordinates for certain locations (the hard ones to find, or ones with seemingly contradictory sources) so that you have a starting point to validate my decisions beyond the Linked Data. Finding coordinates for modern locations represents the bulk of the time I spent on this project; many of these locations took hours of research to locate, and I cite over 400 different sources.
Goal 4: Quantify uncertainty
Even after this research, however, it wasn’t always possible to find exact coordinates for modern locations. Therefore, I also provide my estimate of how close the coordinates in this dataset are to the actual coordinates. Sometimes the best-available coordinates aren’t exactly where they should be because archaeological datasets predate GPS, or the datasets just don’t try to be more precise.
On the other hand, while modern locations have positional uncertainty, ancient places come with their own set of uncertainties.
About 150 ancient identifications are described as “near” somewhere else, which I attempt to quantify based on context (in some cases, “near” might mean 1 km, and in others it might mean 10 km or more).
But more significantly, scholars just aren’t sure where many biblical places are. Since a goal of this project is to document all the possibilities, the question then becomes how to decide which identifications are most likely. My solution, which has substantial room for improvement, involves looking at the change in confidence over time.
I assign a numerical score for each confidence level (e.g., a “Yes” vote from a source counts for 30 points, while a “Likely” vote counts for 24), sum the scores from each source, normalize the scores (where 1,000 represents near-certainty), and then group them together into decades. In theory, the resulting composite score reflects the confidence of scholarship for a particular identification during that decade. Then, if you draw a best-fit (linear regression) line across the decades, you can see where the scholarship is trending. The number I use for determining confidence levels reflects the value of this best-fit line in 2020.
When we look at a chart expressing the data for Gath of the Philistines below, for example, the trendlines largely reflect what you’d expect if you’re familiar with the controversies over its identification: around the 1950s, it was identified with Tel Erani, but later archaeological discoveries have shifted the identification definitively away from there and likely to Tell es-Safi. Other good examples of shifting confidences are Ai and Anaharath.
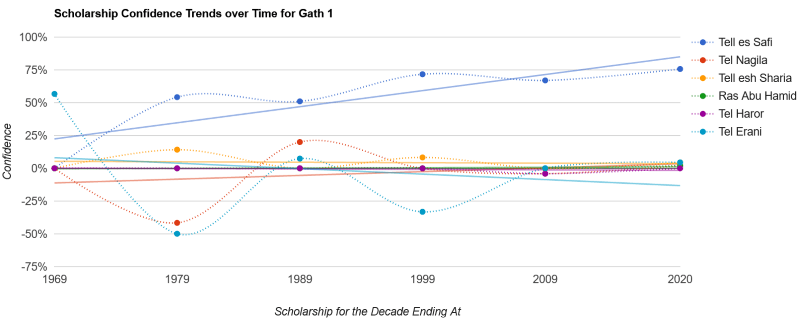
The main problem with this approach is that a line doesn’t necessarily model the data well, 77% of the time, the r-squared value is less than 0.5, meaning that confidence doesn’t get consistently higher or lower with time but rather jumps around. See Abel-keramim, for example.
There are other options for generating confidence. For example, I could sum the overall confidences over time so that the lines move higher as time goes on. However, because the number of sources varies by decade, the lines jump in ways that don’t necessarily reflect the underlying confidence levels. I decided that using line charts was the least-misleading way to approach the data, imperfect though it may be.
Goal 5: Handle non-point data
This vote-based approach to modeling uncertainty also extends to regional geographic data. Regions in the past didn’t necessarily have the sharp political boundaries we think of today, and they varied over time as their territory waxed and waned. Thus, while it’s nice to present tidy historical boundaries on a map, reality was messier. We can still try to quantify the messiness, however.
I chose to approach the problem of regions not from a historical or political perspective but from a cartographic one. Instead of answering the question, “What are the boundaries of this region?” I instead answer the question, “Where should I put a label for this region on the map?” And it turns out that this latter question is answerable using a methodology like the one I used for place identifications.
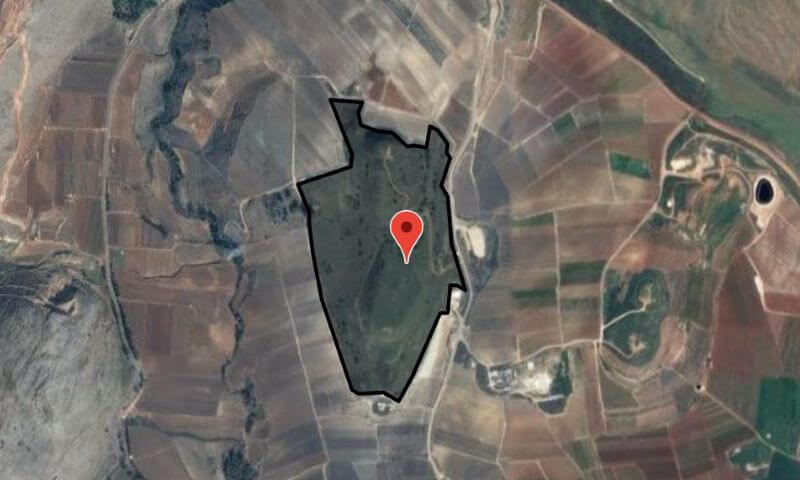
I took about 70 different Bible atlases and other reference works and recorded polygons roughly where the region labels or boundaries appeared. (This approach involved a lot of interpretive looseness on my part: I wanted to emphasize the commonalities among the different sources.) Here’s what the labels for the region of Ammon look like, for example:
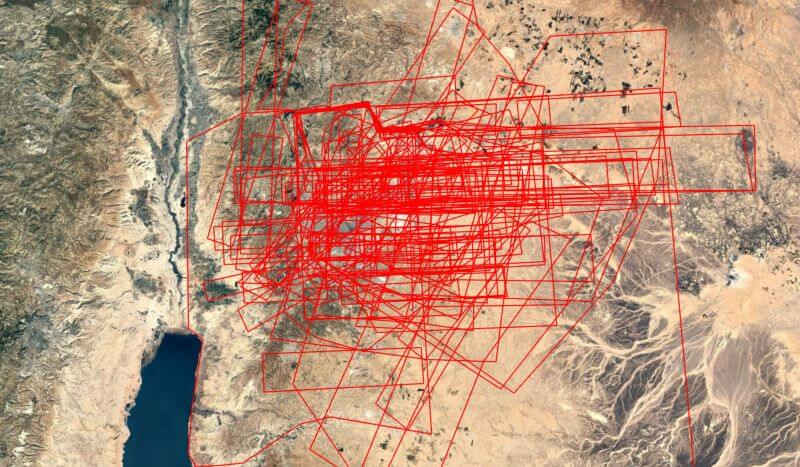
Then I combined the polygons from the different sources to create a confidence heatmap: for example, “four sources suggest this point was in the region, but only three sources support this point over here.” The resulting concave-hull isobands (with each line indicating the number of sources supporting the position of the region, so inner isobands reflect a higher confidence) yields useful information about not only where to put a label but also the rough—very rough—extent of a region. The following isobands for Ammon, for example, draw from sixteen sources and show its core territory around Rabbah, as you’d expect. The outermost isoband reflects confidence levels from two sources, while the inner reflects confidence from ten or more. Thus, if you were looking to place a label on this map for “Ammon,” your best bet would be in the innermost polygon, but anywhere inside the isobands would reflect a consensus placement.
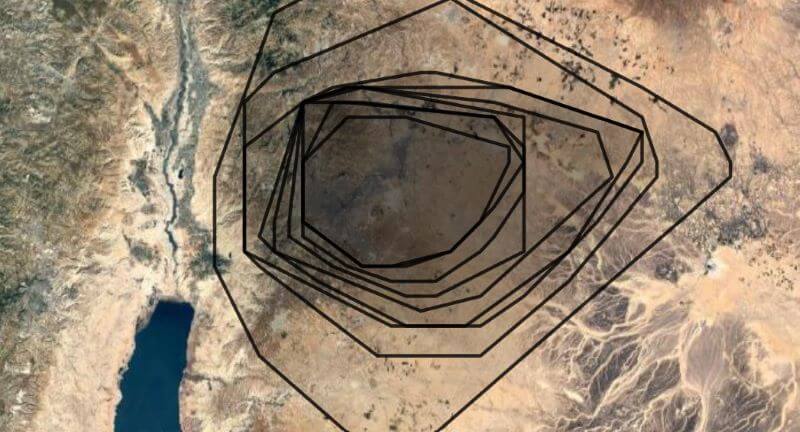
Ultimately, I created 3,545 polygons to generate 77 isobands files. Not every ancient region is controversial enough to justify isobands; this dataset contains 238 region files in total.
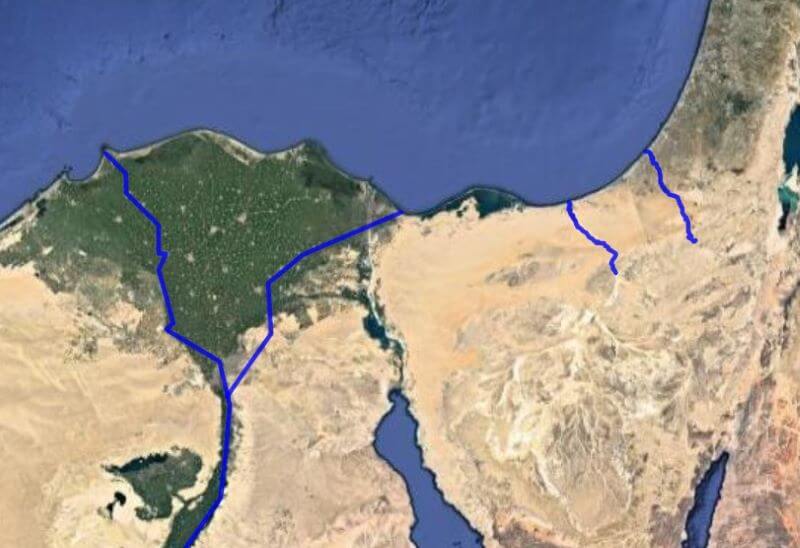
In addition to regions, there’s also path data, especially for rivers and wadis. The previous version of this dataset treated them as points, but OpenStreetMap already had paths for many of the relevant rivers, and when the OSM data didn’t already exist, I created it there. In total, about 120 paths have geometry in this dataset; I made 91 edits to OSM as part of this project.
For example, here are the paths of possible identifications for the Brook of Egypt (for display, I reduce all paths to around 100 segments, but the dataset also contains the full geometry from OSM):
Goal 6: Include media
The final major component of this dataset is the inclusion of an image to represent every modern location: there are about 1,650 512×512-pixel “thumbnail” images that are freely available to use. Just over 1,000 of them are drawn from Wikimedia Commons, while the remaining have a satellite image (with a resolution of 10 meters per pixel) illustrating the area surrounding the location. Honestly, Wikimedia Commons had more images than I was expecting: many of these locations are pretty obscure.
About 50 images illustrate an ancient region. (For example, the best thumbnail for the region of Gilead probably isn’t one of an archaeological site that happens to be in the region.)
Locations with Wikidata items often had images associated with them. In other cases, the WikiShootMe tool provided a way to find untagged images of the location (or sometimes an artifact associated with the location). Once I had a viable image, I cropped it into a square and potentially adjusted the colors or used Photoshop’s Content-Aware Fill tool to edit it for consistency and to be more legible at small sizes. The dataset also records license and attribution data as presented on the Wikimedia Commons page for each image.
To create the satellite images, I used Sentinel-2 composites from 2019. Sentinel-2 is a European satellite; its 10-meter-per-pixel resolution is just enough to illustrate the general character of a location (e.g., desert vs. wooded, hilly vs. flat). The resolution is lower than what you see on Google Maps but is freely reusable.
All images have descriptive alt text since accessibility is a modern application of Christian charity. The images themselves also have accessibility and license and attribution data embedded in them.
I struggled most with finding images to illustrate regions. Below, for example, is what I chose for the Sharon Plain; it shows that the region is coastal, flat, and agriculturally fertile, but depicting a whole region using a single image will necessarily be reductive.

{kind=link}
Goal 7: Open the data
All the data is available in a GitHub repository with a 7,000-word readme describing the (unfortunately complex) data structure. My hope is for you to do something interesting with it. It’s under a CC-BY license, though the images are under a variety of Wikimedia-approved free licenses (as noted in the metadata), and the OpenStreetMap data is under a CC-BY-SA-style ODbL license. GitHub isn’t ideal for data projects like this (though it does have an integrated GeoJSON viewer), but I wanted a stable, long-term host that doesn’t make you jump through hoops to get the data.
The dataset currently contains files for (the totals may change over time):
- Ancient places (1,342 entries).
- Modern locations (1,596 entries).
- Geometry (6,621 GeoJSON and KML files) and metadata (588 entries for non-point data) for both ancient places and modern locations.
- Images (1,650 jpegs) and image metadata (2,424 entries—there’s metadata for images considered but not included, as well as pointers to some copyrighted images, especially Google Street View).
- Sources consulted (442 entries).
- JSON Schemas to validate the rest of the data (5 schemas).
Beyond the 175 MB of images, you’ll find 100 MB of geometry data and 16 MB of core data.
The only data omitted from the repository is the raw vote data (“Anchor Yale Bible Dictionary found this particular identification to be ‘likely’”) because I want to supplement—not replace—my sources; if you want to find out how Anchor Yale Bible Dictionary identified a place, the data shows you where you can look it up in your own copy. This project transforms and interprets raw data, bringing together different perspectives and uniting different datasets, both in print and online. To save you time in your research, I want to point you to scholarly sources where you can learn more about the arguments for various identifications.
Limitations
This dataset has a number of limitations:
It builds on the work I did in 2007 to disambiguate places mentioned in the Bible. While I reworked many of the places (e.g., I didn’t realize in 2007 that there’s more than one Rabbah), I didn’t revisit the disambiguations from scratch.
The disambiguations also showcase a limitation to the data model. If two places in the Bible share a name, but my sources disagree about which one a certain verse is referring to, then I created a third place with identifications pointing to the other two. There aren’t really three possible places; the third one exists only because the data model requires it. For example, Ibzan’s hometown of Bethlehem 3 is likely Bethlehem 2 or possibly Bethlehem 1, not a third Bethlehem somwhere.
Similarly, some sources may consider a place the same as another one, while other sources may mention the modern location associated with the other place but not make the ancient connection explicit. I recorded the identification as described in the sources, but it leads to situations where the same modern location appears in multiple identifications, as part of both “another name for an ancient place” and “at this modern location” identifications. For example, Timnah 3 has Khirbet et Tabbaneh both as a possible identification for Timnah 2 and as a separate, modern identification.
While I’m confident that the spelling of biblical place names correctly reflects the text of the translations they appear in, spellings of modern locations are less validated. They could easily contain typos (where the typos exist in a source, I note it). They also reflect a variety of transliteration approaches from the nineteenth century to today. The primary modern name depends on whether it’s unique in the dataset, not whether it reflects the dominant name used in the sources. (For example, Bethsaida could be at at-Tell while Ai could be at et-Tell, names that reflect different transliteration approaches from Arabic into English of the same underlying name.) Additionally, I don’t know Hebrew or Arabic, so the transliterated diacritics I preserved could be wrong. I focused on simpler transliterations and thus didn’t usually preserve some more scholarly aspects of transliterations like breathing marks.
River geometry is always a single path, even if the river has branches. This limitation is most apparent on large rivers like the Nile, whose geometry doesn’t reflect the delta as it approaches the Mediterranean.
The identifications depend on my reading comprehension, interpretation, and conversion of freeform text into structured data, not to mention my limited sources and research abilities. The identifications don’t have the kinds of checks and balances a more-formal research project would entail. My goal was 90% accuracy.
Originally, I’d hoped to provide a wiki-style interface to the data, where people could contribute. But the data is so interrelated—it relies on a 45-step build process from raw spreadsheet to final form—that such functionality went beyond the scope of what I could accomplish. The identifiers also rely on static data snapshots and don’t incorporate improvements to, say, Wikidata that have appeared since I first pulled the data from there. The result is less dynamic than I’d originally hoped.
Advancements over the current state of the world
This project attempts to advance the state of the art along the following dimensions:
- Number of identifications. With 23,000 votes for the locations of ancient places, this project reflects a broad (if heavily evangelical) survey of current thinking. And with 3,259 distinct identifications, it has around six times as many identifications as the typical Bible atlas. However, Bible atlases provide context and interpretation that this project lacks; I’m not trying to replace a Bible atlas, only to provide supporting data.
- Precision of coordinates. With 87% of coordinates identified to within 250 m, the precision in this project outshines the best-case 1 km precision (often just a prose description) found in most Bible reference works.
- Number of Bible translations. Ten Bible translations reflect a variety of spellings and translation approaches, reducing reliance on the ESV (compared to the 2007 version of this dataset). The NLT, for example, likes to use place names in verses where other translations instead might say something like “there.” In total, 5,616 verses contain at least one place name, with 87,988 total name instances tracked across all ten translations.
- Integration with external resources. Linking to existing databases like Wikidata creates an outward focus and enables future work, with 6,536 ancient connections and 6,473 modern connections.
- Images. Every modern location has a thumbnail image, with 1,014 of the 1,650 photos being an on-the-ground, close aerial, or artifact photo, and the remainder being a medium-resolution satellite image.
- Transparency of data. With sources cited and data available, you should have what you need to trace my conclusions if you have the relevant sources available to you. (I tried to include links to online sources where possible.) I provide 1,251 comments providing more information in difficult cases.
Benefits to you
If a place is mentioned in the Protestant Bible, it should be in this dataset. You can look it up in the interface by passage reference or name and quickly get a sense of where modern scholars think it could be, as well as how confident they are in the identification. Often the possibilities cluster tightly (Penuel, for example, is probably on one of two neighboring hills, even though one is more likely than the other); if you only need to know an approximate location (which, unless you’re doing in-depth study, is almost certainly all you need), then you’re set. But if you want to know more about the possible locations and how confident my sources are in their identifications, that data is also available to you. I want to encourage you to purchase print or digital books that you find helpful to deepen your study of Bible geography; the dataset includes links to Amazon and other sites like Best Commentaries, sites whose stable urls also provide a further kind of Linked Data.
Interface
The data went live on this site in January 2021, and an interface that showcases it went live in September 2021. Looking at how people use the site has led to some data changes. For example, when I first launched, I didn’t provide proposed locations of the Garden of Eden, just calling it “unknown.” But after seeing how often people look it up, I treated it like any other place and provided potential identifications.
The 2007 version of the interface emphasized downloading Google Earth KMLs for individual books and chapters. For this update, I want to encourage exploration of the data even if you don’t have Google Earth. Therefore, I’ve changed the interface to let you interact with the data in five ways:
1. Book/chapter view
This view lets you see a bunch of places at once so that you can get a sense of how geography fits into the narrative. It includes:
- A map of all the places mentioned in the book or chapter.
- A way to drill down into a single chapter if you’re looking at a whole book.
- A clickable list of all the places (including verse references and potential modern identifications) to explore on another view or on the map on the same page.
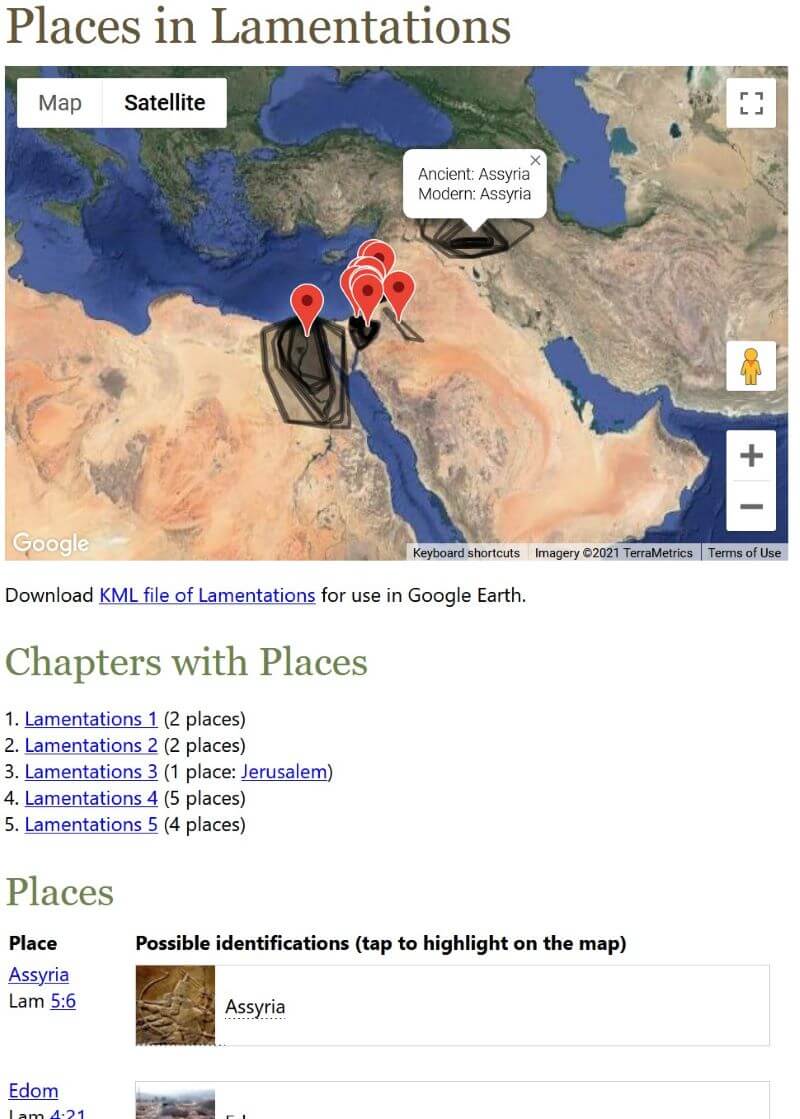
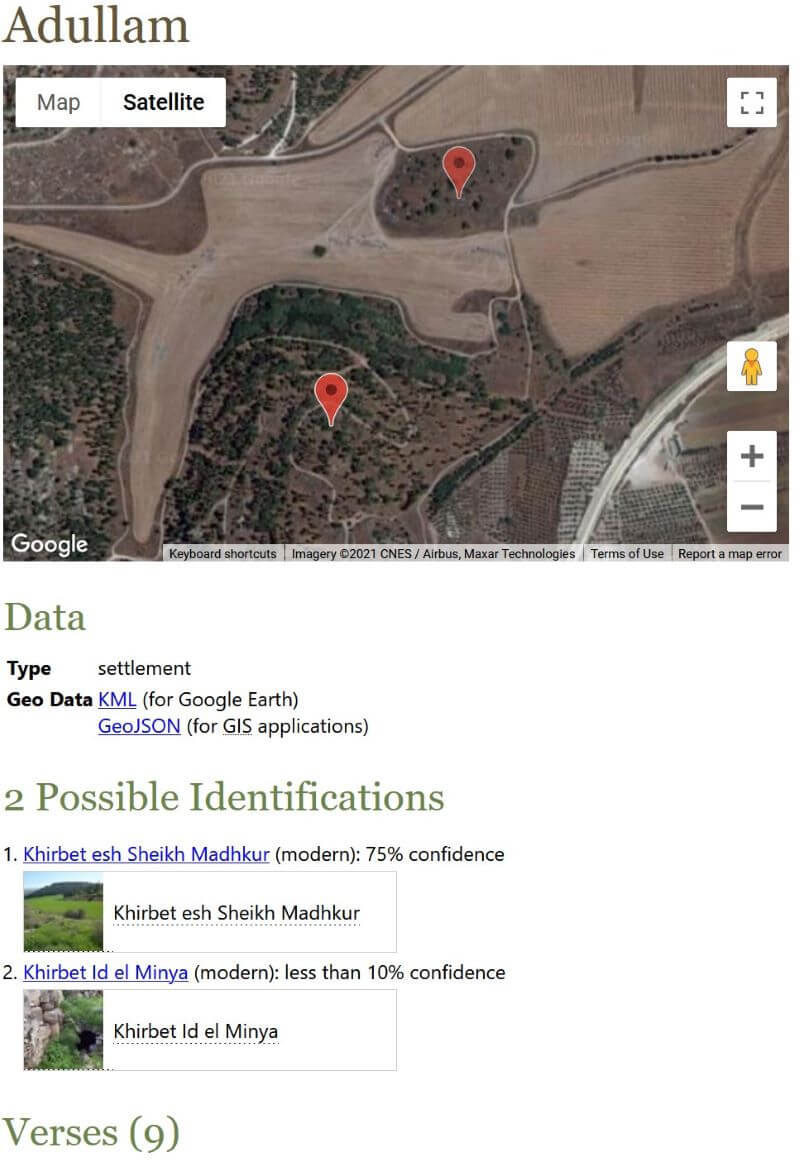
2. Ancient place view
This view presents data about ancient places mentioned in the Bible. It includes:
- A map of possible identifications, with placemark pushpins varying in opacity depending on the confidence of the identification.
- Any alternate names found in Bible translations.
- Geo data (KML and GeoJSON) for the identifications.
- All the identifications and their corresponding confidence levels.
- Bible verses where the place appears.
- Linked Data identifiers.
- Sources supporting the identifications.
- A graph of confidence trends over time.
- Links to similarly named places (especially since the numbering system I use—“Aphek 1,” “Apkeh 2,” etc.—is fairly opaque).
- A thumbnail image when the identification is noncontroversial.
3. Modern location view
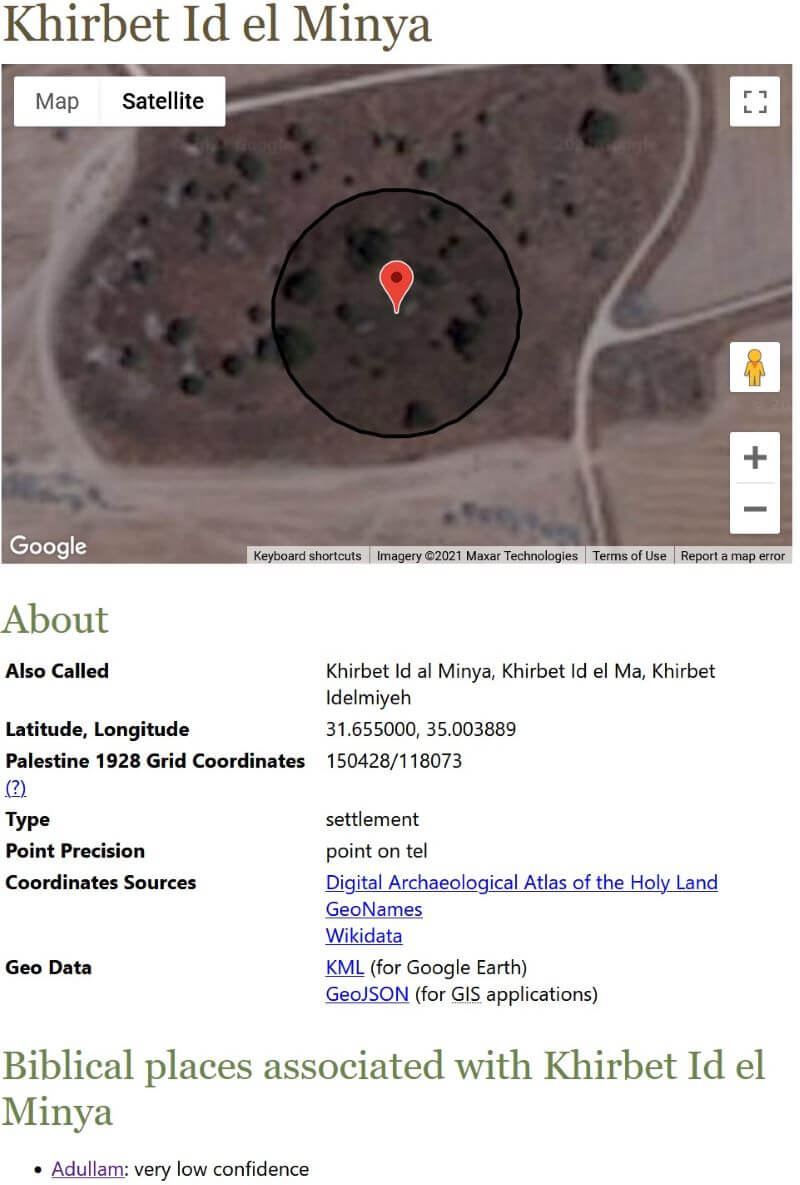
This view presents data about modern locations identified with ancient places. It includes:
- A map showing geometry (point, path, polygon, or isobands), including polygon geometry of an archaeological site if it’s available (e.g., Colossae).
- Alternate names (usually different transliterations but sometimes names in different languages, such as Hebrew or Arabic).
- Latitude and longitude coordinates.
- Palestine 1928 grid coordinates, where relevant; most Bible reference works use this coordinate system.
- Coordinate precision (how close to the actual location the coordinates are).
- Sources supporting the coordinates.
- Accuracy and precision notes.
- Biblical places associated with the location.
- A thumbnail image.
4. Atlas view
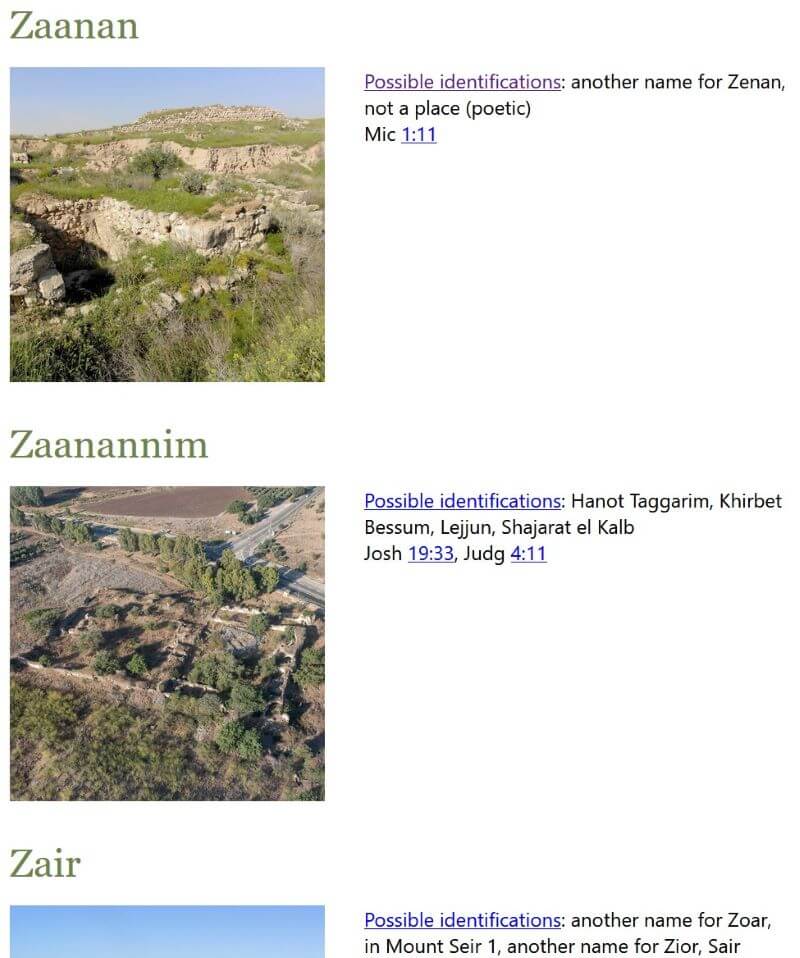
This view is an alphabetical list of all the ancient places. It includes:
- A thumbnail image of the most-likely modern location.
- A list of possible identifications.
- Bible verses where the place appears.
5. Photo view
This view is mostly for legacy compatibility. Previously, I used the Flickr and the now-defunct Panoramio APIs to pull in photos that are geographically near the coordinates, but the result was hit-or-miss. Now there’s a single photo for each modern location associated with an ancient place. I wouldn’t include this view except for historical reasons; I don’t consider it very useful.

Conclusion
It’s 2021. Bible reference works shouldn’t have to say that a ruin is, for example, “on the left side of the road from Salt to Amman, 1.5 hours [by horse] northwest of Amman.” And then you shouldn’t have to spend three hours figuring out exactly where that is, consulting the original 1822 travelogue that makes this claim, and then trying to determine exactly where the road ran in 1822 compared to modern roads. Instead, we should be able to say that that a ruin is at particular coordinates with a certain level of precision. And then we should be able to tie that ruin back to a biblical location with a quantifiable degree of confidence. This project lets us do that.
Environmental impact
Creating this data required about 800 kWh of electricity in computing power and local travel. All the electricity used was solar-generated; carbon emissions totaled about 40 kg. Book shipping generated an additional 103 kg of carbon emissions. The total carbon impact for this project is therefore approximately 143 kg; I don’t have tools at my disposal to be more precise than that. I include this statement just to note that data, even Bible data, has an environmental impact.
Thank you so much for this outstanding resource. I just posted a link to it on my blog: https://bibleandtech.blogspot.com/2021/11/bible-geocoding-and-rethinking-bible.html
(I am so grateful for your work, so I really hate to mention it, but by chance I did come across an error. Apollonia is mislocated by about 7 miles. The geotag on the picture you have linked with it is correct. Even more precisely at 40.64315838726306, 23.489279533756665 there is a monument to Paul’s visit and remains of the Via Egnatia.)
Good catch regarding Apollonia. The Pleiades coordinates I was relying on were imprecise, and sometimes the best coordinates are indeed from a geolocated photo. I updated the coordinates on the site and gave you credit. Thanks!