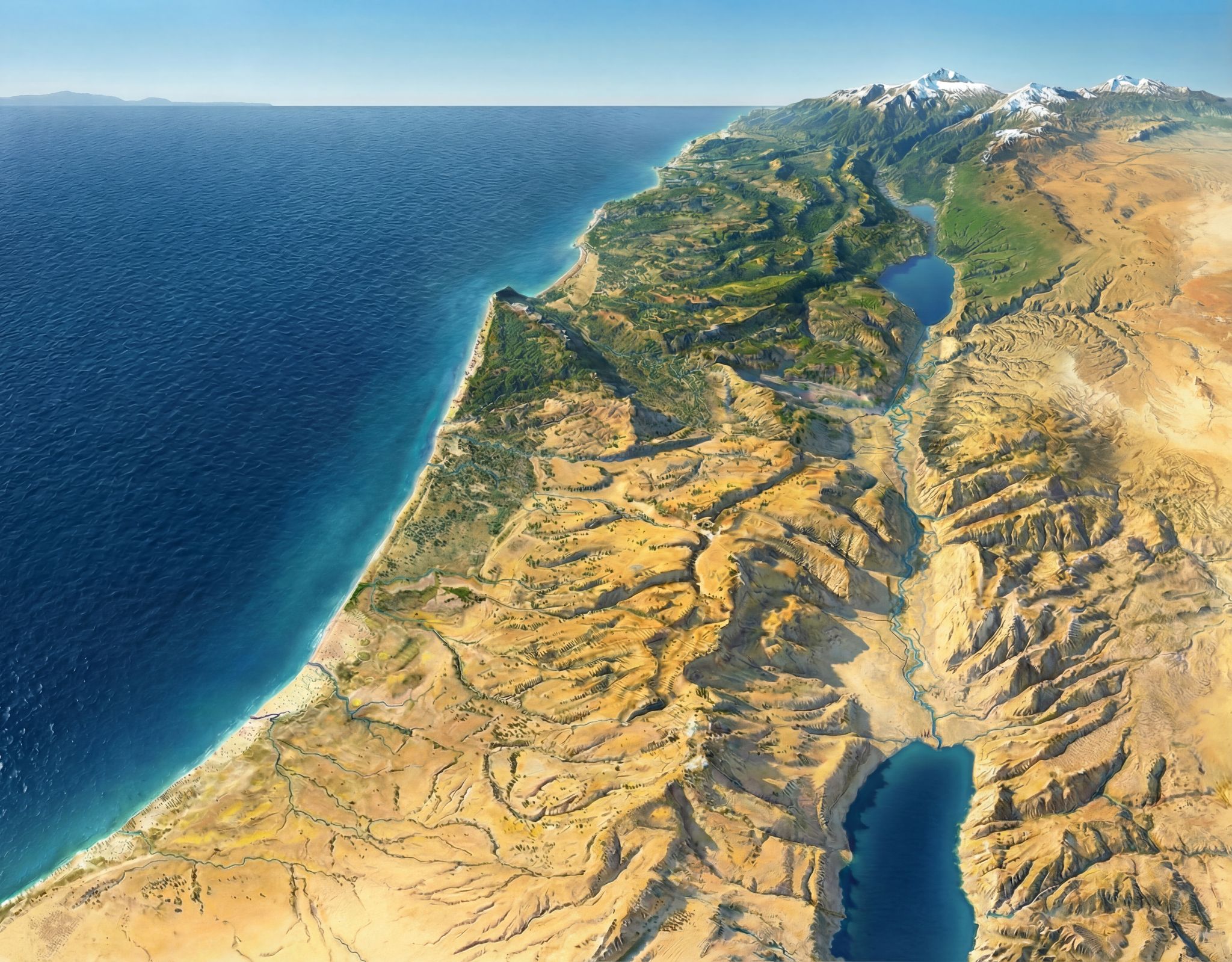
Nano Banana Pro can rewild photos of archaeological sites with AI; it can also create rewilded maps. For example, here’s a fake satellite view of the Jerusalem area with all structures, roads, and anything human-created removed:

And georeferenced in Google Earth:
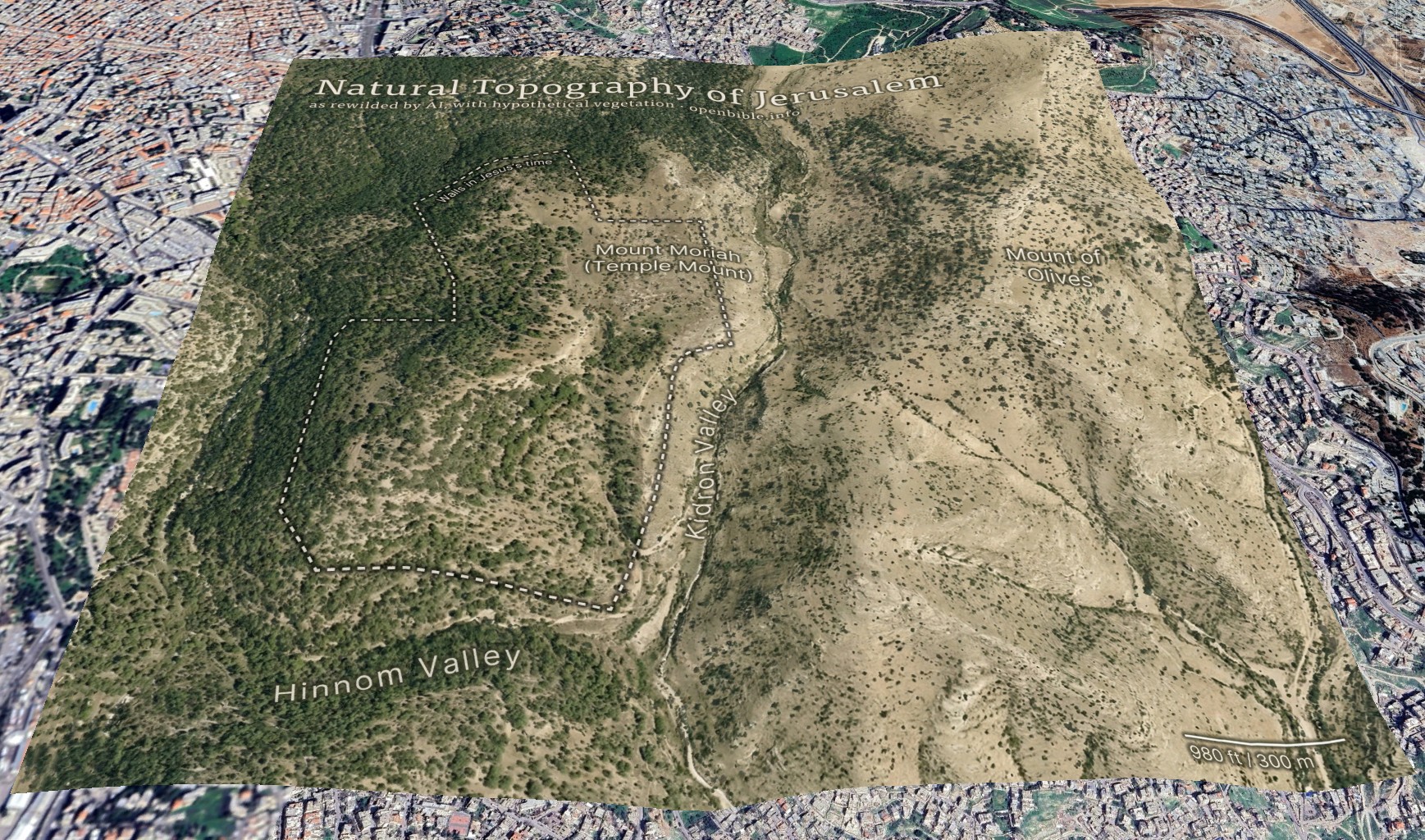
AI enables creating this kind of map in a few hours, rather than the weeks it would have taken using traditional methods.
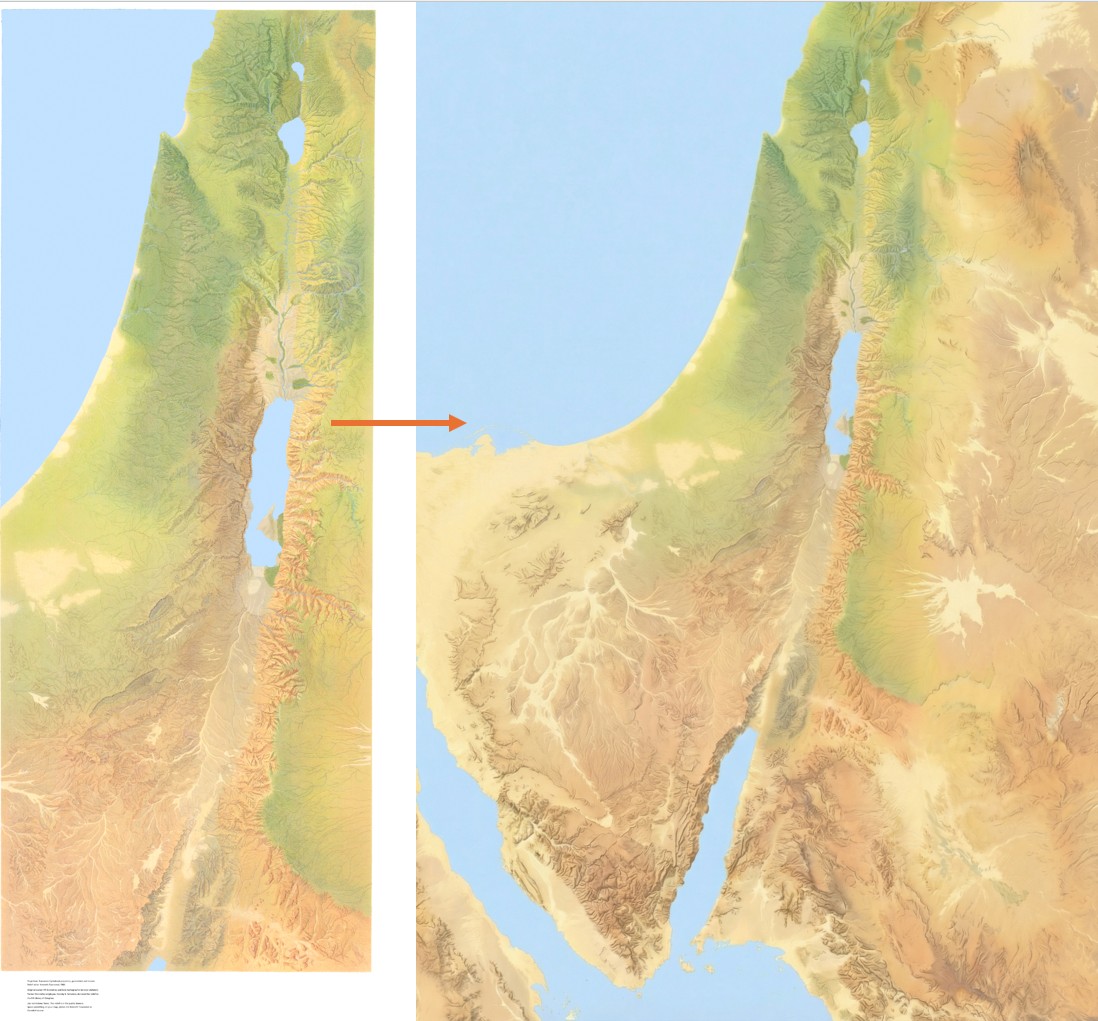
The effective resolution of this image is about 1.2m per pixel, equivalent to a high-resolution (and therefore expensive) satellite photo. (A true satellite photo would show mostly urban development here, of course, and wouldn’t be terribly useful for visualizing the underlying landscape.) The topography is mostly accurate; the vegetation coverage is speculative.
Methodology
First, I needed a relatively high-resolution topography for the area around historical Jerusalem: approximately 2.3km by 2.3km (about 2 square miles). The highest-resolution free Digital Elevation Models are 30m per pixel, which at this latitude gives a grid of about 100 x 100 elevation pixels. While that may not sound like a lot, it’s enough to create a final 2,048 x 2,048-pixel image—but the low resolution of the source data also reinforces how much the AI is inventing fine surface detail.
I started with the GEDTM30 global 30m elevation dataset (which, as a DTM, aims to give bare earth elevations, excluding buildings and landcover). Using these instructions, I created 5m contour intervals in QGIS and exported them to a png. I compared these contours with 5m GovMap contours; they differed in some details but were plenty close enough for this purpose.
Here’s where Nano Banana Pro came in. I gave it the contours and the following prompt (the “text” in the prompt refers to the contour elevation labels):
This is a detailed map of the area around Jerusalem. Convert it to an overhead aerial view. Preserve all the topography exactly. Remove all text. Apply landcover (especially trees and scrub) in a naturalistic fashion and show bare dirt, light scrub, and trees where hydrologically appropriate.
Smooth out all the elevation lines—there are only smooth hills, no terraces or cliffs. Use the elevation lines as a reference, not to create terraces. No terraces should be visible at all; just smooth them out.
The idea is to make it look natural, without any human developments.
As you can tell from my pleas in the prompt, Nano Banana Pro really liked making terraces (since the contour intervals look like terraces). I ended up generating twenty-four iterations but used the seventh one because it preserved the topography of the City of David especially well. Each generation had different pluses and minuses—some were better at color, some at vegetation, and some at hydrology. That’s part of the beauty of using AI: it allows rapid iteration and many generations at low cost. This project cost about $5 in total.
I also explored giving it a version of the DTM itself (with the elevations scaled to grayscale values 25 through 244), as well as a hillshaded version. Nano Banana Pro gave me roughly comparable results for each, but I preferred how the contour versions turned out.
With a 2,048 x 2,048-pixel png in hand, it was time for Photoshop. I used the spot healing brush extensively to remove visible terraces. I also went back to Nano Banana Pro to generate trees and scrub for certain areas, brought in parts of other discarded generations, and used Photoshop’s built-in generative features in some places. You can definitely see artifacts from my editing if you look closely at the finished map. I also added an exposed rock (just visible under the “m” in “Temple” in the above map) where the Dome of the Rock now stands.
Then it was off to Illustrator to add the text and the outline of the city walls. ChatGPT gave me a few pointers to refine the look.
Finally, I georeferenced the map in Google Earth and consequently adjusted some of the wall placement in Illustrator to align the wall more precisely with structures that are still visible today.
Discussion
I’ve never used an AI + real data workflow like this one before. It would’ve been prohibitively time-consuming to create this map without AI, which is part of the ethical question around using AI. Did I “steal” the hundreds or thousands of dollars I might otherwise have paid a cartographer-artist to create this map? More realistically, I never would have created it at all.
The map’s high degree of realism could lead people to believe that it reflects reality more than it does; at first glance, you could easily take it for a real satellite photo. The landscape that it depicts never looked exactly like it does in the map. This combination of extreme realism with plausible hallucinations captures the current state of AI in a nutshell: it looks real, but it isn’t.
The map depicts a pre-human landscape (thus the “rewilding”). Biblically, it’s closest to how it might have looked in Abraham’s time, before subsequent urbanization. But even during his time, there still would be settlements, visible footpaths, grazing areas, small-scale agriculture, and potentially less forest.
Nano Banana Pro’s interpretation of the elevation data is reasonable. I feel like it made some of the eastern hills ridgier than they are in reality, however.
It also did a good job with the trees and scrub, though they’re much more speculative than the topography. I chose, artistically, to forest the western half of the map more than the eastern half, since Jerusalem approximately marks where denser vegetation in the west would yield to sparser vegetation in the east. I may have gone too far in either direction—too much forest in the west and too little vegetation in the east.
Data
You can download a jpeg of the map with and without labels. The unlabeled version is available as a geotiff for your own GIS applications. I also added both the labeled and unlabeled versions to the Map Overlays for Google Earth page, where you can download a KML to explore them in Google Earth.





























{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}