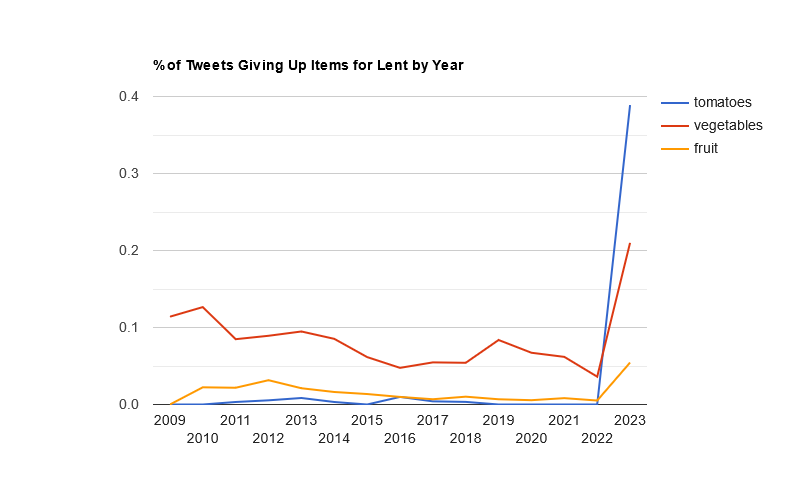
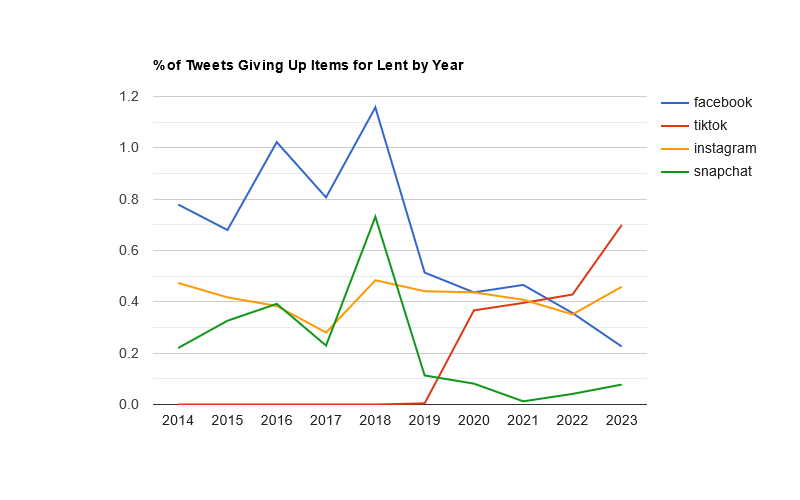
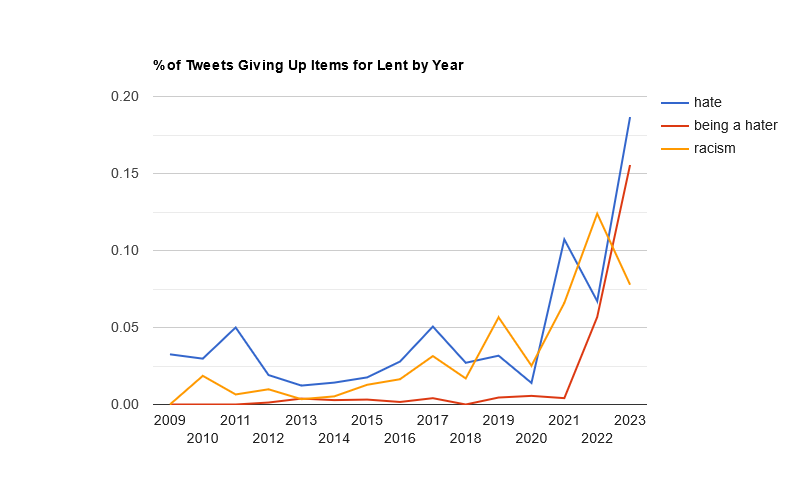
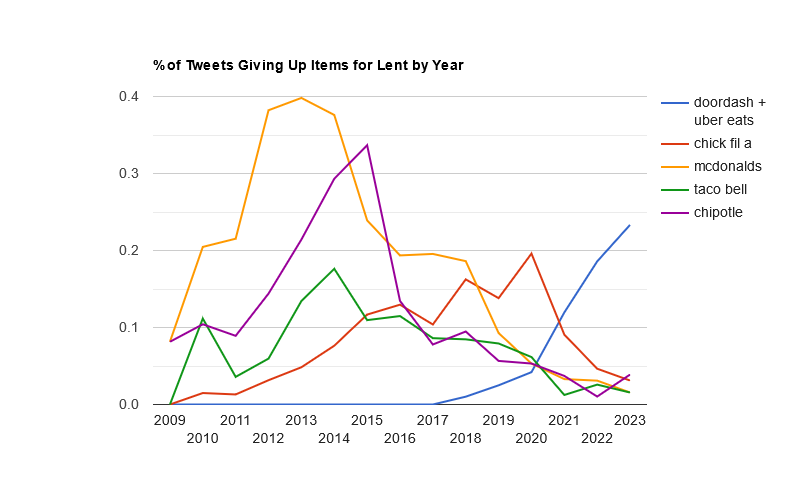
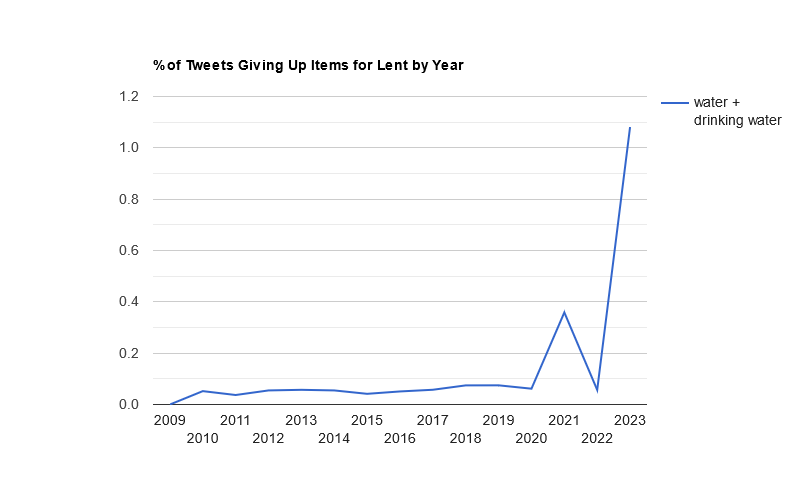
This year, the usual trio of Twitter, social networking, and alcohol led the list, with Twitter taking the #1 spot for the first time since 2021.
This report draws from 9,817 tweets, the lowest number of Tweets I’ve ever tracked and down from a high of 646,000 in 2014. It only took ten tweets to make the top 100 this year, compared to 228 that year. On the other hand, the list of items in the top 100 has remained fairly stable: 56 of the top items from 2014 are also in the 2024 list.
Relationships
With Ash Wednesday falling on Valentine’s Day this year for the first time since 2018 (next time will be 2029, and then not again until 2170), relationship-related tweets rose. This year saw an increase in “situationships,” though it didn’t reach the top 100.


Sin
Giving up sin had a big uptick this year. I don’t have an explanation.

The Press
U.S. President Joe Biden said that he was giving up “you guys” for Lent, a reference to reporters.

Taylor Swift
Only eight tweets mentioned celebrities this year; seven of them were for Taylor Swift.

Top 100 Things Twitterers Gave Up for Lent in 2024
| Rank | Word | Count | Change from last year’s rank |
|---|---|---|---|
| 1. | 413 | +1 | |
| 2. | Social networking | 348 | +1 |
| 3. | Alcohol | 341 | -2 |
| 4. | Lent | 238 | 0 |
| 5. | Chocolate | 199 | 0 |
| 6. | Sweets | 164 | +4 |
| 7. | Meat | 142 | +7 |
| 8. | Giving up things | 142 | +7 |
| 9. | Swearing | 127 | -3 |
| 10. | Coffee | 113 | -3 |
| 11. | Soda | 112 | -3 |
| 12. | Sugar | 107 | +6 |
| 13. | Sex | 86 | -2 |
| 14. | Lying | 71 | +11 |
| 15. | Smoking | 70 | +8 |
| 16. | Men | 70 | -6 |
| 17. | Fast food | 59 | -5 |
| 18. | Marijuana | 57 | -5 |
| 19. | Catholicism | 50 | 0 |
| 20. | Candy | 47 | +7 |
| 21. | Religion | 47 | -1 |
| 22. | Work | 46 | -6 |
| 23. | Red meat | 46 | +15 |
| 24. | Sin | 45 | +36 |
| 25. | Bread | 42 | 0 |
| 26. | Chips | 41 | -2 |
| 27. | Liquor | 40 | -6 |
| 28. | Love | 40 | +31 |
| 29. | Valentines day | 38 | |
| 30. | Tiktok | 37 | -14 |
| 31. | 36 | -8 | |
| 32. | You | 34 | -10 |
| 33. | Food | 34 | 0 |
| 34. | Sobriety | 32 | +6 |
| 35. | Life | 32 | -1 |
| 36. | Beer | 32 | -6 |
| 37. | The press | 31 | |
| 38. | Complaining | 29 | +10 |
| 39. | Hope | 29 | -2 |
| 40. | Hate | 22 | +4 |
| 41. | Gambling | 21 | +8 |
| 42. | Procrastination | 21 | +9 |
| 43. | Him | 21 | -14 |
| 44. | Yearning | 20 | +24 |
| 45. | Cookies | 20 | +9 |
| 46. | Fried food | 20 | -6 |
| 47. | Booze | 20 | -6 |
| 48. | Carbs | 19 | -1 |
| 49. | Masturbation | 19 | -18 |
| 50. | Junk food | 19 | -3 |
| 51. | Porn | 18 | -2 |
| 52. | Ice cream | 18 | +2 |
| 53. | Christianity | 18 | -5 |
| 54. | Caffeine | 18 | -19 |
| 55. | Hard liquor | 18 | -3 |
| 56. | Energy drinks | 18 | +4 |
| 57. | Gossip | 17 | -1 |
| 58. | Vaping | 17 | -13 |
| 59. | Pork | 17 | -6 |
| 60. | Losing | 16 | -7 |
| 61. | Desserts | 16 | -6 |
| 62. | Snacking | 16 | -12 |
| 63. | Coke | 15 | -12 |
| 64. | Being gay | 15 | -14 |
| 65. | My will to live | 15 | -9 |
| 66. | Homework | 15 | -20 |
| 67. | Meat on fridays | 14 | |
| 68. | Sanity | 14 | -14 |
| 69. | Being a hater | 14 | -21 |
| 70. | TV | 14 | -11 |
| 71. | Video games | 14 | -17 |
| 72. | Rice | 14 | -20 |
| 73. | New Year’s resolutions | 13 | -12 |
| 74. | Celibacy | 13 | -14 |
| 75. | Negativity | 13 | -13 |
| 76. | Dairy | 13 | -20 |
| 77. | Church | 13 | -21 |
| 78. | Reporters | 12 | |
| 79. | Pizza | 12 | -26 |
| 80. | Online shopping | 12 | -30 |
| 81. | 12 | -42 | |
| 82. | Sarcasm | 12 | -22 |
| 83. | Women | 12 | -34 |
| 84. | Fizzy drinks | 11 | -19 |
| 85. | Being nice | 11 | -24 |
| 86. | Cocaine | 11 | -22 |
| 87. | Gooning | 11 | -19 |
| 88. | Donald Trump | 11 | -20 |
| 89. | Wine | 11 | -42 |
| 90. | Breathing | 11 | -38 |
| 91. | Dating | 11 | -29 |
| 92. | Eggs | 11 | -28 |
| 93. | Nicotine | 10 | -42 |
| 94. | Depression | 10 | -36 |
| 95. | Scrolling | 10 | |
| 96. | Posting | 10 | -31 |
| 97. | People | 10 | -57 |
| 98. | Being single | 10 | -38 |
| 99. | Anger | 10 | -33 |
| 100. | Cake | 10 | -39 |
Top Categories
| Rank | Category | Number of Tweets |
|---|---|---|
| 1. | food | 1,698 |
| 2. | technology | 953 |
| 3. | smoking/drugs/alcohol | 712 |
| 4. | habits | 612 |
| 5. | irony | 573 |
| 6. | relationship | 329 |
| 7. | religion | 212 |
| 8. | sex | 210 |
| 9. | politics | 83 |
| 10. | school/work | 79 |
| 11. | entertainment | 67 |
| 12. | money | 45 |
| 13. | health/hygiene | 34 |
| 14. | shopping | 25 |
| 15. | sports | 24 |
| 16. | possessions | 8 |
| 17. | celebrity | 8 |
| 18. | weather | 4 |
| 19. | clothes | 1 |